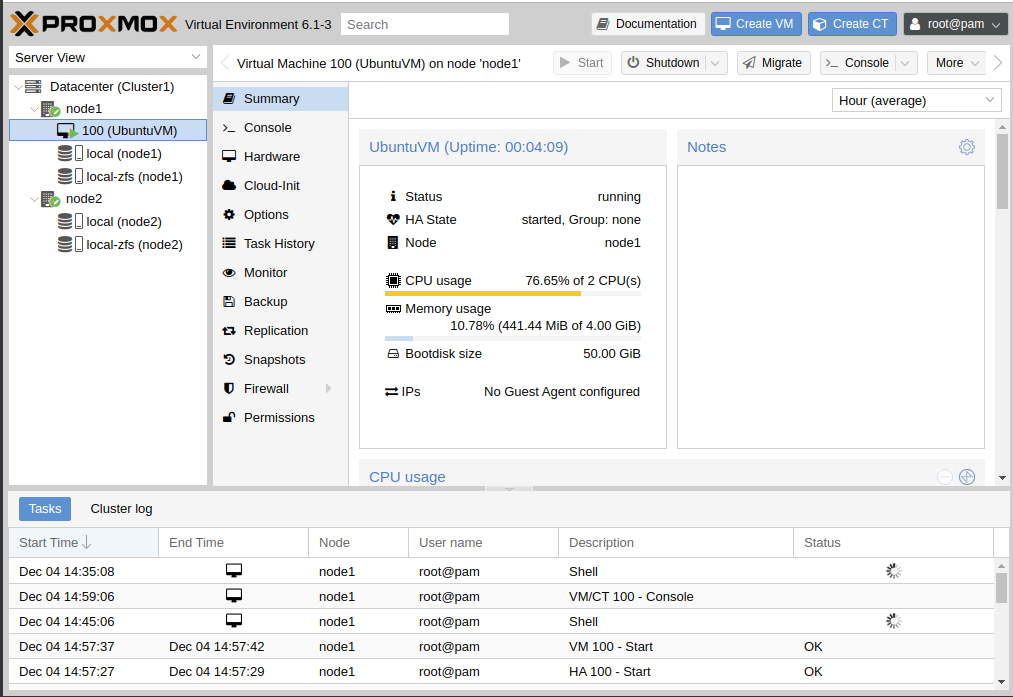
I was recently tasked with creating a small deployment to host a single virtual machine at a customer site. The purpose of the virtual machine was to provide us with remote access to a specific customer resource that was otherwise unavailable to us. The deployment consisted of two physical machines running as Proxmox hypervisors (node-1 and node-2) hosting a single virtual machine. The virtual machine was configured to be replicated from node-1 over to node-2 every 5 or 10 minutes and was added as a HA resource. Side note: in order for replication to work, you need a ZFS filesystem. If you instead are using shared storage, replication is not needed.
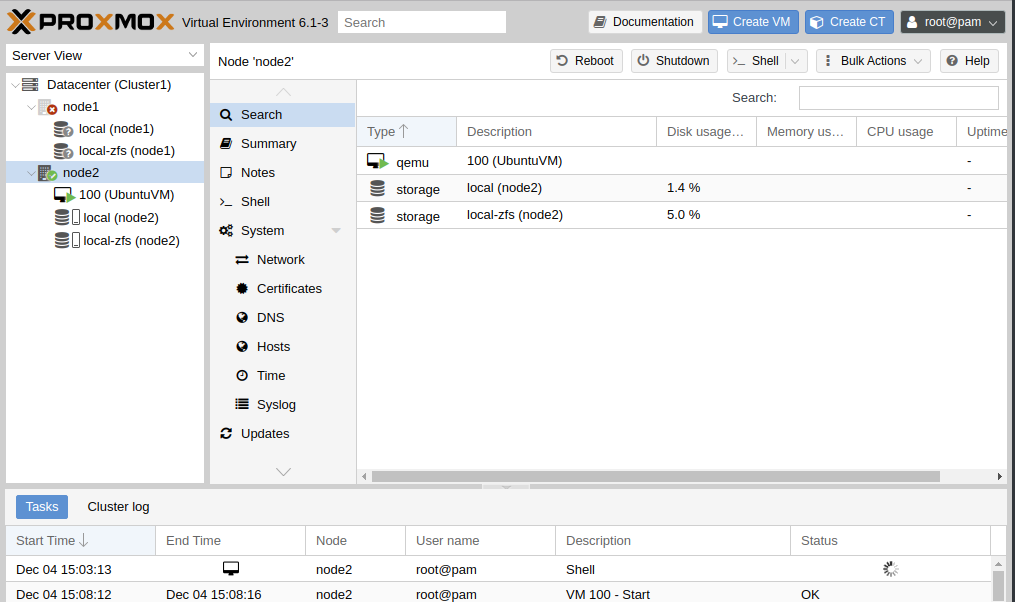
The reason for this configuration is to provide some redundancy & resiliency to handle one of the nodes failing in some way. We can also more easily back up, snapshot, and restore the virtual machine when needed. Having the virtual machine replicated gives us the ability to migrate it over the other node quickly. However, one major issue I had with this setup is that automatic failover does not work in a two node cluster. Proxmox requires three nodes for a quorum, and a quorum is needed before any automatic HA migrations are triggered. Unfortunately, I could not justify the extra cost of adding a third node to make a full cluster and I did not want to throw in some cheap hardware to function as the 3rd node. So, I instead wrote a python script to provide the functionality I needed.
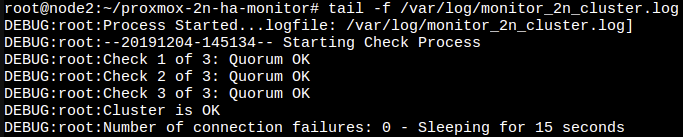
The script checks the status of the cluster every 60 seconds using the ha-manager status command. If the returned status indicates that the quorum is NOT OK for n number of occurrences (n can be defined to be any number), the script will manually set the expected quorum votes to “1”. This triggers HA services to start the virtual machine on the remaining node.
Now, this certainly is not a perfect solution, but is working out wonderfully for me in this scenario so far. Using this script could open you up to the possibility of the virtual machine being started on both nodes. For example, if there is temporary networking issue preventing the two nodes from communicating with each other, they will each see the other is down and start the virtual machine.

You can check out the script here: http://gitlab.rickelobe.com/virtualiztion/proxmox-2n-ha-monitor.git